
Training a machine to play simple paddle ball game using Deep-Q Learning algorithm with Keras
This project demonstrates training a machine to play simple paddle ball game using Deep-Q Learning algorithm with Keras.
This article is intended for beginners.
Pre-requisites
- Python (tested on 3.6)
- Keras
- Theano/Tensorflow
- pygame
Source code
https://github.com/azhar2205/paddle-ball-using-dqlearn
How it works (in context of paddle ball game)?
While playing game each action taken in a state (move left, move right, don’t move) impacts the total points obtained at the end of the game. The goal is given a state, select an action such that the future result is maximum.
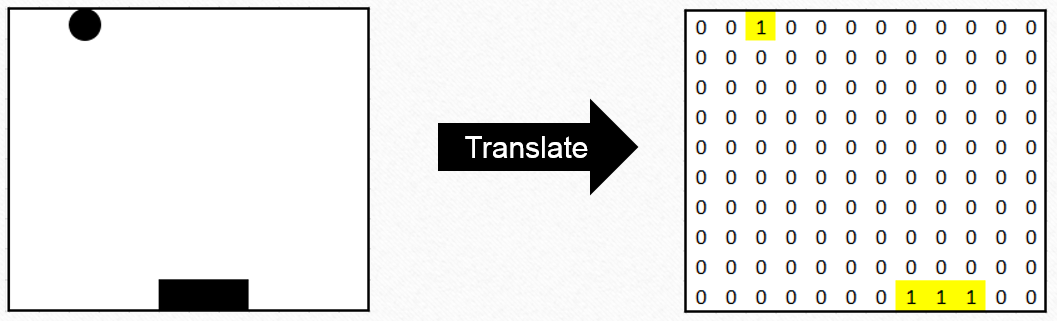
Lets represent the game screen with a 2-D array. The array elements wrt the position of the ball and the paddle are “1”s. Rest all values are “0”s.
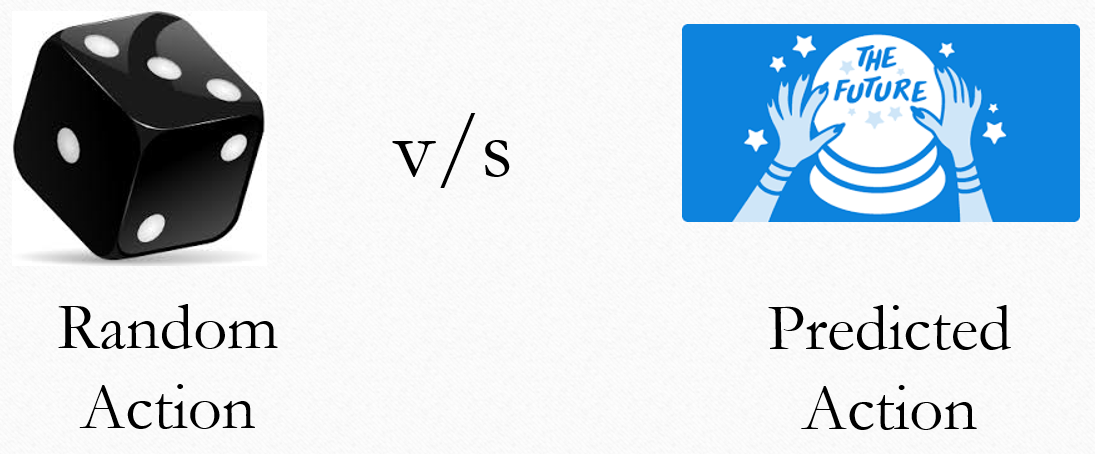
Next step is to decide what action to take. We use neural network to predict reward for each action and select action with maximum reward. However if we just depend on neural network for the next action, then we will be restricted to only to those predicted actions. There can be an action which may give better rewards which is not predicted by machine. So during game play, sometimes we use a random action instead of the predicted action. (This problem is called Exploration-Exploitation dilemma).
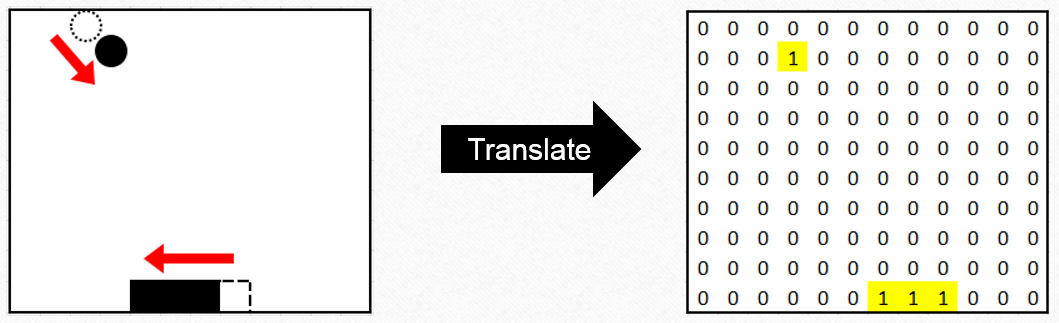
Once the action is decided, update the state according to the action i.e. move paddle as per action, and continue ball’s journey as per trajectory.
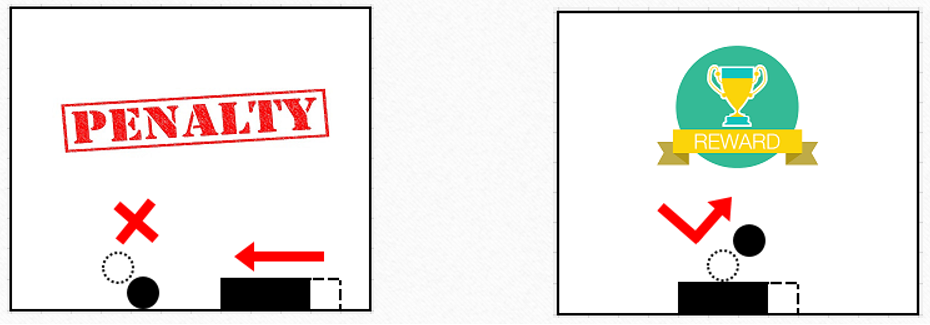
The action will result in some point gain (ball is bounced off the paddle) or point loss (ball touches ground) or no point change (ball is in air).
Store the tuple <current state, action, reward, next state> in FIFO queue. Neual networks have tendency to adopt to recent training (and hence forget earlier learnings). To fix this, the entries in queue will be used to re-train the neural network. (This process is called Experience Replay).
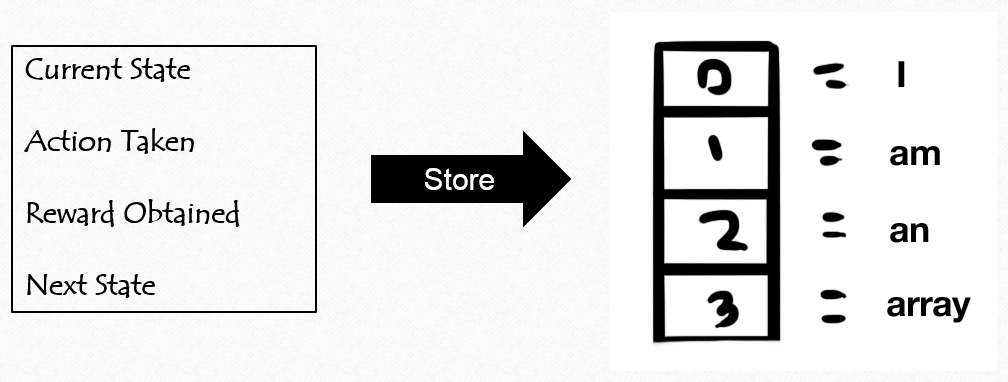
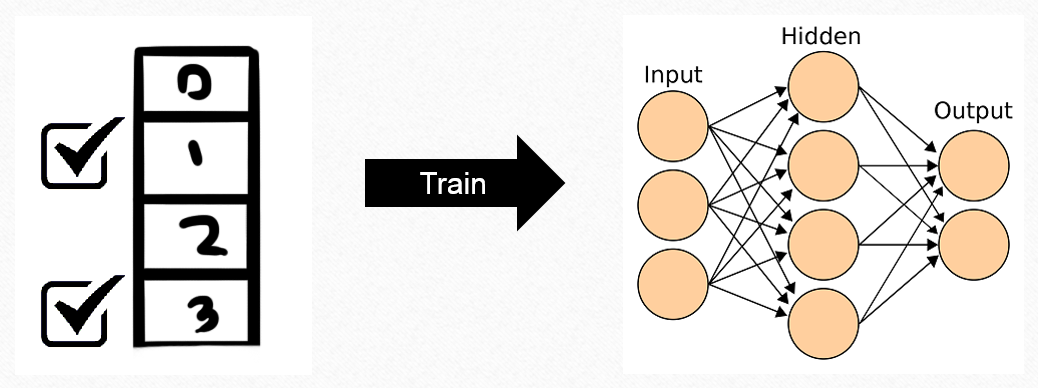
There is one more importance step done during Experience Replay. The target of the neural network (i.e. the reward for an action) is set to the computed maximum reward (aka Discounted Future Reward). The neural network learns to match output closely to expected Discounted Future Reward.
It is highly recommended to refer this post.
References:
Guest Post (Part I): Demystifying Deep Reinforcement Learning - Nervana
Deep Reinforcement Learning: Pong from Pixels
Using Keras and Deep Q-Network to Play FlappyBird - Ben Lau
Keras plays catch, a single file Reinforcement Learning example - Eder Santana
GitHub - asrivat1/DeepLearningVideoGames
Deep Reinforcement Learning: Playing a Racing Game - Byte Tank